Audio-Visual Speech Separation via Bottleneck Iterative Network
Presented in ICML 2025 Workshop on Machine Learning for Audio.
Introduction
We introduce a new AVSS model, Bottleneck Iterative Network (BIN), that iteratively refines the audio and visual representations using their fused representation via a repetitive progression through the bottleneck fusion variables and the outputs of the two modalities from the same fusion block. Tested on two popular AVSS benchmarks, BIN strikes a good balance between speech separation quality and computing resources, being on par with RTFS-Net’s state-of-theart performance (and improving on SI-SDR) while saving up to 74% training time and 80% GPU inference time. Our code is available on Github.
Intuition
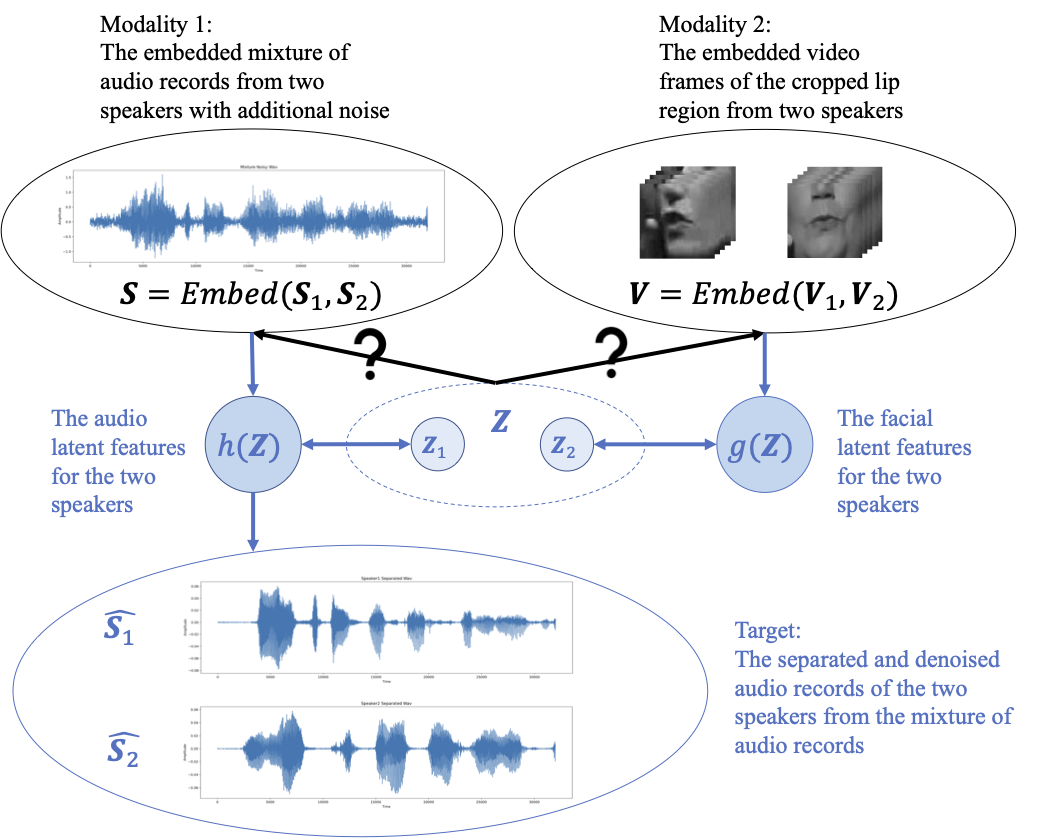
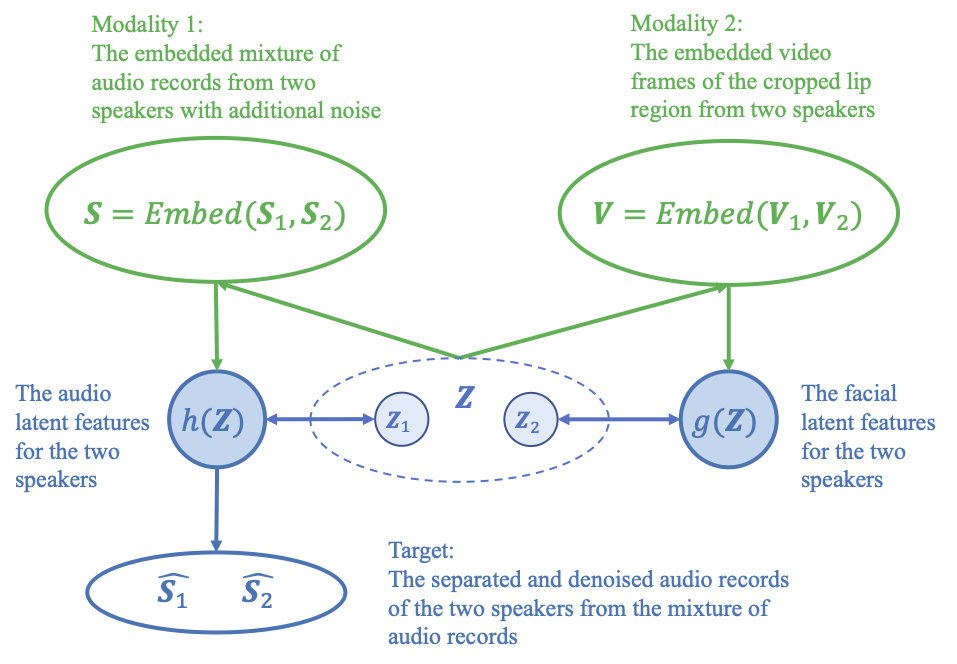
A traditional fusion method focuses on learning representations from unimodal inputs and fusion spaces (blue arrows in the plot), but lacks bringing the fusion and late representation information back to the early embedding space (black arrows with the question marks in the plot).
This backward connection can be important. Consider an audio-visual speech separation (AVSS) task where For example, a female speaker says “WE MUST ADOPT THAT WAY OF” while the other female speaker says “THEY’RE LIKE THE BASEBALL SCOUTS 20 YEARS”, but because of the distortion from the noise and the tones of the two speakers, the two phrases sound close to each other at the beginning words “WE MUST” and “THEY’RE”. With no backward connection, the required information at the early stage might be lost or compressed too much to be recovered correctly in the final fused latent representations. Meanwhile, a backward connection adds back the fused late latent representation to the original embeddings as residuals, then process the combined reprenstation again to get a refined used latent representation, so the early information is constantly added to avoid information loss.
Paper Citation
@misc{zhang2025audiovisualspeechseparationbottleneck,
title={Audio-Visual Speech Separation via Bottleneck Iterative Network},
author={Sidong Zhang and Shiv Shankar and Trang Nguyen and Andrea Fanelli and Madalina Fiterau},
year={2025},
eprint={2507.07270},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2507.07270},
}